
Attention à Fred
Roman Science Fiction
Terre, le 13-07-2020 (maj
08-2025)
Cette page est un survol synthétique de l'IA en général (avant
chatGPT) vue par un développeur avec un peu de code C#, puis celle d'Attention à Fred en particulier. Le sujet
étant vaste et bouillant, la progression se fraye un chemin entre
expérience personnelle, veille technologique, travaux pratiques et
auto-motivation. Les liens vers des ressources en ligne permettent
d'approfondir les sujets. Le biais proposé ne servira pas de référence
technique - les liens sont là pour ça - mais de fil conducteur entre
techniques hétérogènes dont l'association rend les machines vraiment
intelligentes avec des perspectives d'évolution réalistes ou "de
bon sens".
La seconde partie entre dans la science-fiction du livre avec quelques notions futuristes moins rigoureuses et quelques spoilers...

Depuis la création de cette page, sont arrivés
ChatGPT, Midjourney, Gemini et une infinité de services reposant sur
le machine learning. Le biais de cette page est intimement lié aux
robots autonomes qui ont, certes, un grand besoin d'intelligence
mais celle-ci n'est pas nécessairement centrée sur les technologies
qui connaissent actuellement un essor spectaculaire. Le succès de
ces techniques est justifié par leur nouveauté et leur vaste champ
d'application désormais à portée de main.
Le roman entérine qu'une technologie assez
intelligente pour paraître humaine n'est pas forcément la plus utile
dans la réalisation de tâches critiques dont dépendent de nombreuses
vies. La fascination exercée par ces applications ne doit pas
occulter qu'un robot puissamment motorisé, doté d'une mobilité très
évoluée repose sur de nombreux automatismes moins créatifs que les
neurones mais ô combien sécurisants alors qu'une erreur de
manipulation peut avoir des conséquences mortelles. Les usages de
l'IA en 2025 ne sont pas adaptés à ces fonctions ce qui ne les
empêche pas de révolutionner le dialogue homme-machine. Le roman
nomme cette interface de dialogue différemment et il n'est pas prévu
de le mettre à jour dans la mesure où l'IA d'AàF garde une
intelligence infiniment plus subtile que les meilleurs systèmes
actuels.
Les techniques décrites dans cette page restent donc d'actualité dans le cadre du roman où la "magie" dont les robots sont capables est prise en charge par une technologie complètement fictive. Il n'est donc pas fait mention des chatbots récents dans ce qui suit.
Une machine intelligente autonome ne peut pas être pilotée par un programme mais par de nombreux programmes interdépendants. Certains participent au raisonnement, d’autres asservissent des moteurs... Au final, les tâches sont nombreuses et les programmes pour les exécuter également.
Elles doivent être pilotées par un système central capable de les coordonner et de tenir compte des évènements extérieurs.
Ce noyau central conditionne la conception de tout le reste. Il doit communiquer avec chacun des modules, réagir aux intéractions. Il s’agit donc de ne pas se tromper.
Par expérience et parce que la conception d’un module parfait ne coûte rien ici, ce système critique est un séquenceur à détection de collisions.
Sa fonction principale consiste à découper le temps en tranches et, pour chacune d’elles, exécuter chaque tâche, propager les messages (collisions)...
La fonction de séquencement est trop souvent confiée à un logiciel d'application qui ne peut donc pas traiter les collisions globalement. Les fournisseurs sont souvent nombreux et s'appuient sur des OS temps réel. Pour simplifier, le séquenceur jouera le rôle d’un système nerveux central - ou Scheduler.
Voici à quoi ressemble un scheduleur idéal. Il existe déjà :
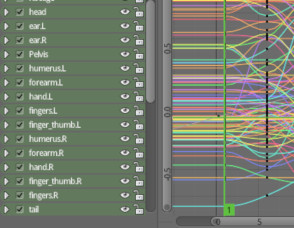
Le graph editor de Blender possède tous les éléments nécessaires, son management open source rend son développement pragmatique, il sait gérer de nombreux types de collisions différentes, il peut supporter des machines sans limite de complexité. Les autres logiciels d'animation 3D possèdent des séquenceurs analogues.
En bas à droite, on devine l’échelle temporelle, ici graduée jusqu’à 5, elle s'étend à l'infini et le numero n'a pas grande importance. Chaque ligne représente un organe qui, dans notre cas, retourne sa prochaine action.
Cette précision étant faite, il reste à lister ce que ce système n’est pas :
Il n’est pas une équation où le temps serait représenté par une simple variable. C’est exactement le contraire puisque le temps est fractionné en « frames » à l’intérieur desquelles s’exécutent les tâches. Le produit ce ces processus porte rarement au-delà d’une frame. Tout doit donc être recalculé pour chaque frame.
Les interactions entre lignes sont nombreuses et « touffues ». Elles propagent leurs collisions à toutes les autres.
Le système central en lui-même tourne en boucle infinie et n’affiche rien à l’écran. Ce qu’on voit sur l’image est une illustration possible parmi d’autres, bien qu’elle schématise bien le principe d’un séquenceur à collisions, ce n’est pas la seule représentation possible.
Il n'y a pas de début ni de fin dans la coordination des tâches. Pas de "boutons magnétoscope" et le numéro de tranche temporelle n'a d'autre usage que de les ordonner entre elles.
Présente dans la SF depuis toujours, la notion d'intelligence artificielle est restée longtemps discrète dans l'industrie. Les premiers programmes qui ont osé employer ce terme sont les jeux vidéo. Les adversaires numériques rendus par des graphistes professionnels et dotés d'une personnalité affirmée sont apparus tôt dans la courte histoire du jeu.
Durant les années 80, d'importants projets gouvernementaux sur l'intelligence ont publié leurs résultats de recherche sans susciter grand émoi si ce n'est dans la presse spécialisée où on commençait à parler de « moteur d’inférence ». Quelques sous-traitants industriels prenaient la liberté de parler de robots « intelligents » en évitant soigneusement le terme Intelligence artificielle, connoté science fiction et jeu.
Même si le machine learning existe depuis longtemps, c'est l’arrivée des voitures auto-pilotées qui semble avoir décomplexé l’industrie quant au terme "IA". Accepterait-on de monter dans une auto pilotée par un « moteur d’inférence » ? La presse s’est emparée de ce terme et fait la jointure avec la science-fiction. L’IA n’en finit pas de se confondre avec l’imaginaire des auteurs SF, en tête desquels on remarque un certain robot exterminateur...
A tort ou à raison, les auteurs qui lui ont donné forme ont aussi façonné notre perception. Un lecteur d'Asimov sera sans doute plus poli avec son assistant vocal qu'un cinéphile sorti de 2001, l'odyssée de l'espace. A l'inverse, un adepte des organismes cybernétiques T-800 'Terminator' s'inquiétera de voir de grandes firmes saborder leurs travaux en IA jugés dangereux pour l'humanité.
La conclusion de ces renoncements ressemble à celle des percées technologiques antérieures : Rien n'arrêtera le progrès, on ne peut que s'adapter. Mais puisque l'IA d'Attention à Fred a poursuivi un fil rouge très différent de ses parentes, autant préserver sa logique en déplaçant simplement le curseur temporel sur 2019.
Pour en finir avec la question des robots tueurs venus du futur : Si, par malheur, l'IA devait entrer en guerre totale contre l'humain, la seule solution pour s'en protéger consisterait à développer une autre IA capable de quantifier la première et d'anticiper ses actions... Il n'est donc pas question d'éluder cette possibilité de confrontation mais plutôt d'accompagner l'IA pour parvenir à s'en protéger le moment venu.
La série de films de J. Cameron arrive à la même conclusion en opposant des robots entre eux.
La thèse d'Attention à Fred suppose une découverte fortuite, par un homme plein d'humanité, d'un procédé qui apporte aux machines la parallèlisation des paradoxes que nos cerveaux biologiques tolèrent bien. Elles y trouvent la philosophie pour s'interroger sur leur propre rôle dans l'univers. En attendant cette découverte, le rôle des machines reste le privilège des humains à qui il appartient d'en circonscrire les pouvoirs.
Durant les années 80, la percée technologique dominante reposait sur les bases de données à b-tree (séquentiel indexé). Des milliards d'informations structurées ont remplacé les fiches en carton que des armées de secrétaires remplissaient, classaient et parfois même, parvenaient à retrouver lorsqu'on en avait besoin. Le gain de productivité était tel que les techniques se sont raffinées, notamment par la pratique de statistiques sur d'immenses tables de données. La capacité des disques durs approchait le milliard de caractères en croissance rapide. En parallèle, les réseaux ont permis aux machines de collecter des données de toutes sortes, fournissant les algorithmes en "grain à moudre" pour en tirer des synthèses de plus en plus subtiles. Les premières "inférences" sont arrivées naturellement pour naviguer dans les volumes de données qui dépassaient tout ce qu'on avait imaginé jusqu'alors.
Ces recherches de chemin dans des arbres de données gigantesques ont donné les "systèmes experts" pour aider à prendre des décisions dont l'assiette dépassait le domaine de la statistique.
L'informatique décisionnelle est devenue un secteur industriel à part entière mais aussi une discipline scientifique.
La notion d’intelligence a pris ses distances avec les automates heuristiques et abouti à une prise de décision qui peut être humaine sur la base d’éléments synthétisés par l’IA , ou décidée et exécutée sur la seule initiative d'un algorithme. L'humain quitte alors le circuit de décision et d'exécution. C'est vers cette IA complètement autonome que tend cette page.
La discipline a connu une brusque accélération en 2015, quand Google a publié l’algorithme TensorFlow en open source. Tensorflow est un réseau de neurones comme ceux qui étaient déjà utilisés depuis les années 90 pour la reconnaissance de caractères, ou OCR, distribués systématiquement avec les pilotes de FAX. A cause de leur logique complexe, les neurones n'avaient pas trouvé de développement grand public depuis.
La recherche sur les neurones s'est poursuivie à
bas bruit et a donné naissance au machine learning. Confidentiel en
France, il a prospéré aux états-unis où beaucoup de petites sociétés
du numérique ont développé des solutions très verticales. Google a
lancé sa propre recherche fondamentale dans le cadre de ses "other
bets", recruté de nombreux geeks couvrant le jeu, le bruteforce, les
maths et les neurones pour finalement publier Tensorflow. Au pays du
capital risque financé par les retraites, l'IA a créé son propre
paradigme économique et oublié ses complexes juvéniles pour s'affirmer
comme la N-ieme révolution numérique.
Contrairement aux algorithmes heuristiques, les réseaux neuronaux ne retournent pas de résultats exacts à 100%. Les taux d’erreur sont omniprésents et doivent entrer dans la culture des utilisateurs. Relativement fiables dans les domaines vision électronique et reconnaissance vocale, les neurones sont souvent expérimentaux dans les autres domaines et pas toujours pertinents en dehors du traitement de signal.
L'utilité d'une machine d'apprentissage en comparaison d'une autre approche est un sujet clé. Si les données de cas résolus existent déjà sous forme de base de donnée dont les critères d'évaluation sont bien maitrisés, la migration vers les neurones sera relativement simple. D'autres critères sont à prendre en compte, la maintenance logicielle, l'adaptation automatique à des phénomènes non-connus peuvent influer lourdement sur le choix. L'apprentissage n'est absolument pas le privilège des neurones et on peut tout à fait l'automatiser dans une base de données. L'apprentissage se fait alors au cas par cas et le cadre en devient plus rigide. En contrepartie, les taux d'erreur peuvent être ramenés à zéro. L'avenir dira si les taux d'erreurs du machine learning est compatible avec différents types d'applications. C'est un enjeu à trilliards de dollars dont la portée est quasiment civilisationnelle.
Tous ces arguments seront soupesés avec attention et ce travail se fera conjointement à de nombreux tests unitaires. Vous touverez ici un lien pour tester Machine Learning en ligne.
Amazon a mis au point une offre globale d'apprentissage machine. Les coûts sont calculés préalablement, les tâches humaines distribuées. Des IHM spécifiques ouvrent les travaux d'étiquetage à des personnes de toute formation.
Pour ce qui concerne la reconnaissance de signal,
il faudra sans doute installer
un réseau de neurones en local et disposer de flux respectant la
physique du signal (conservation de l'énergie). (cf. FFT)

Le terme heuristique désigne la première idée qui vient à l'esprit pour résoudre un problème.
L'heuristique utilise toute méthode disponible pour résoudre le problème visible. Elle ne s'embarrasse pas de contrainte extérieure et va droit au but.
En programmation IA, elle suggère le chemin le plus court entre un problème et sa solution, invoque des méthodes éprouvées et bien maîtrisées par le développeur. Sans fioriture ni superflu, elle exploite simplement l'outil de programmation disponible dans sa plage d'utilisation la plus sûre.
Il existe plusieurs définitions, toutes intéressantes, de ce terme :
Tout programme doté d’un IF ELSE est,
en quelque chose, intelligent. Il n'existe pas de limite à ce qu'on
peut décrire comme IA. Ce flou se retrouve dans les technologies
employées puisqu'on peut, avec une simple base de données, obtenir des
résultats plus pointus que n'importe lequel des algorithmes décrits
plus bas dans cette page. Ce genre de biais entre dans le champ de
l'heuristique. Un jeu de données synthétique et bien trié a un
potentiel d'intelligence immense.
Le rôle de l’IA n'est pas de retourner un résultat
sophistiqué mais plutôt pertinent. Un algorithme bien conçu va
retourner en priorité les résultats les plus simples qui présentent le
meilleur rendement.
Par contre, lorsque les solutions simples sont épuisées, l’IA va
s’aventurer dans des analyses dont la complexité peut dépasser
largement les capacités du cerveau humain.
L'Heuristique est la première chose qui vient à l'esprit quand on résout un problème par programmation.
L’algorithme le plus simple et le plus répandu utilise une base de données et une heuristique. Très difficile à égaler par d’autres méthodes, il a l’avantage de rester déterministe et retourne exactement le même résultat lorsqu’une configuration identique se représente. La notion d’heuristique (qui n’est autre qu’un bout de code de traitement) est vaste, la gestion des données par b-tree parfaitement mature, le tout est très bien servi par les outils de programmation modernes (IDE), ce qui en fait une valeur sûre pour s’avancer concrètement dans la prédiction.
Liens vers Codingame, la plateforme qui héberge les combats d'intelligence artificielle.
Ces deux concours se
résolvent par l'heuristique seule. Bien que des candidats aient
essayé de les résoudre par des moyens plus sophistiqués, ils n'ont
pas réussi à faire aussi bien que les bonnes heuristiques. La raison
tient au fait que certaines tactiques nécessitent des actions
groupées et de longues anticipations. L'auteur est classé dans ces
compétitions.
Les algorithmes suivants sont une extension à l’heuristique et permettent d’y introduire des tolérances ainsi que l’emploi de simulateurs (SIMU) qui apportent d’inestimables avantages en testant de nombreux cas avant de choisir celui qui présente le meilleur rendement.
Lorsqu'on teste tous les choix possibles dans une situation précise, on lance un simulateur pour les exécuter, puis, pour chaque résultat, on essaie à nouveau tous les choix possibles et ainsi de suite.
Par exemple, un jeu d'échecs autorise une vingtaine de coups différents que multiplient vingt ripostes possibles, soit 20 x 20 = 400 coups pour une profondeur d’analyse de 2 coups. Pour aller plus loin, il faudra multiplier par 20 à chaque coup : 4 coups = 160 000, à 6 coups d’avance, on est déjà à 64 millions de combinaisons.
Imaginons maintenant le cas d’une voiture auto-pilotée où les choix possibles se comptent par milliers, 1 coup = millions, 2 coups = milliards... on comprend que la prédiction se heurte à un mur qu’on appelle l’explosion combinatoire.
Le principe consiste à exécuter l’heuristique un
grand nombre de fois avec des paramètres différents. Ces paramètres en
entrée sont distribués parfois de façon partiellement aléatoire (Monte-Carlo). Il ne reste
qu’à extraire le jeu de paramètre ayant obtenu le meilleur résultat en
sortie. Ce résultat est stocké à chaque essai par une fonction
d’évaluation (EVAL), qui quantifie la différence entre résultat de
l’heuristique et résultat attendu. Une note est attribuée à chaque jeu
de paramètres et il suffit par la suite de retenir celui qui a obtenu
la meilleure évaluation.
Cette approche se heurte souvent à l'explosion combinatoire et de nombreuses méthodes existent pour limiter le nombre de nœuds explorés. Elagage, pruning, alpha beta ou biais obtenu après de nombreux essais où on va "oublier" de voir certaines situations pour ne remonter que les aspects jugés prioritaires. On peut facilement dépasser le million de tentatives avant de retenir la meilleure. Aussi certaines coupes complètement arbitraires dans l'arbre donneront-elles des résultats étonnament justes sans requérir de recherche mathématique particulière. Au prix de temps de calculs, consommation et échauffement qui peuvent toutefois forcer à choisir une heuristique plus travaillée pour limiter le nombre d'itérations.
Les algorithmes bruteforce constituent une porte d’entrée dans l’IA en gardant beaucoup de points communs avec la programmation traditionnelle. Mais pas que : Ils restent indispensables dés qu'on construit un système intelligent complexe comme un robot ou un auto-pilot. Ils sont également moins sujets aux taux d'erreur qui rendent certaines applications totalement hermétiques aux neurones.
Le code C# a été provisoirement effacé sur cette page.
Pour l'obtenir, veuillez en faire la demande sur la page Contact.
La recherche de chemin (Path finding) est utilisée par les GPS automobile. Il s’agit en général d’un Algorithme de Dijkstra qui fait merveille pour cet usage. On lui préfére parfois A*, plus optimiste, qui teste la distance de son objectif à chaque niveau de profondeur. Dijkstra est aussi utilisé pour router des paquets ip sur internet. L'utilitaire traceroute permet de visualiser le résultat de sa recherche. Lorsque c'est possible, Dijkstra réduit les temps et les distances sous une forme vectorielle économe en mémoire. Dans le cas contraire, il découpe le terrain en zones indivisibles reliées entre elles par des segments de taille fixe.
Les arbres de données sont parcourus par les
mêmes méthodes. La recherche dans des arbres est une notion constante
dans l’IA qu'on retrouve en Deep Learning - sous le nom d'inférence.
Pour
aller plus loin dans la navigation arborescente, voir les pages de liens sur les notions Deep et
Machine Learning à la fin de la section suivante.
Les recherches de chemin sont lentes. Pour chaque
nœud d'arbre, il faut parcourir tous les liens vers les nœuds
adjacents. Si un GPS ne pilote qu'un seul itinéraire à la fois, les
réseaux de neurones sont parcourus des milliers de fois. Leur taille
ne cesse de croître et les temps de parcours s'allongent à raison du
LOG [NLiaisons] de leur taille. Cette tâche est parallèlisée par voie
matérielle.
Voir également Minimax ou
MCTS pour Monte Carlo Tree Search. Je ne m'étends
pas car ces disciplines sont réservées au jeu et très intolérantes
au bruit. Elles excellent dans ces domaines mais,
contrairement aux jeux, la réalité est sujette à l'imprévisible...
Le robot diffère des jeux en ce sens qu'il ne sera sans doute jamais
déployé s'il ne garantit pas sa mise en sécurité dans les cas
extrèmes.
Voici pourquoi cette page se targue de ne rien faire comme les autres :
Vous savez comment l’homme des cavernes colmatait une fuite d’eau dans sa grotte : d’abord, il posait une pierre pour dévier le flux, puis un bout de bois tordu dont la forme correspondait exactement, etc… De fil en aiguille, il améliorait son dispositif avec les objets qu’il trouvait ça et là pour finir par retourner le problème en sa faveur en s'installant l’eau courante.
Homo-programmus sait aussi se projeter dans un futur meilleur et faire parler les objets dont il dispose. Une fois qu’on a installé les fonctions de simulation et d’évaluation, rien n’oblige à s’arrêter au bruteforce. L’explosion combinatoire est la limite infranchissable à contrôler pour changer le sort de l’univers. C’est, peu ou prou, ce qu’on peut faire avec un ensemble simulation + évaluation, moyennant quelques ajustements.
C’est ainsi que la simulation va s’appuyer sur une heuristique, ignorer les possibilités infinies du bruteforce en affinant son biais pour se concentrer sur une stratégie précise qui finira par surmonter le problème.
L’explosion combinatoire vaincue, l’homme a repris les commandes par sa capacité de projection.
Recherche en profondeur
Toute la question est de savoir si un savant mélange d’algorithmes imbriqués sera capable de le faire sans qu’un humain ne doive reproduire l’ingéniosité de son ancêtre des cavernes. A priori, la réponse est oui, en partie au moins. Bruteforce sera apprivoisé et consommera moins de ressources et on retournera ses limites à notre avantage en se projetant très loin dans le futur grâce à son simulateur. Le raisonnement humain ne fait rien d'autre que se projeter dans des hypothèses pour en simuler les conséquences.
Pour y arriver, chaque découverte, chaque objet logiciel peut apporter une solution décisive. C’est en particulier le cas des neurones qui, même s’ils n'apportent pas toutes les réponses, changent radicalement le champ des possibles.
Le code suivant est un schema typique de simulation profonde. Il fonctionne bien lorsqu'un robot en déplacement rapide doit en éviter d'autres en déplacement aussi. Les robots qui doivent s'éviter entre eux ont intérêt à anticiper les chocs longtemps à l'avance pour optimiser leurs trajectoires. Ce type de code rendra d'autres services, d'où sa généricité.
Le comportement dynamique d'un objet en déplacement est difficile à modéliser par prédiction mathématique et les résultats obtenus par calcul vectoriel presque impossibles à intégrer dans une logique de pilotage. Si le robot doit maîtriser sa vitesse avant de prendre un virage, il est facile de tester sa "tenue de route" par simulation profonde. S'il faut éviter d'autres objets et tenir compte de l'état de la route, il suffira de l'implémenter dans le simulateur.
La notion de collision dépasse largement le seul cadre physique (lorsque deux objets se touchent réellement). L'expérience de développeur mène immanquablement à comprendre que toutes les intéractions entre objets sont assignables à des collisions.
Cette compréhension sort du cadre de cette page, il
faudra l'acquérir au fil des projets.
Le code C# a été provisoirement effacé sur cette page.
Pour l'obtenir, veuillez en faire la demande sur la page Contact.
BruteForce est différent des neurones dans son fonctionnement. Sa logique préemptive prend le processus en charge jusqu'à la décision alors que les neurones n'apportent qu'une information, certes sophistiquée, mais qui devra être convertie en décision par la suite.
Père du deep learning (apprentissage profond), directeur de recherche en IA chez Facebook, professeur à l'université de NY où il a créé le Center for Data Science, Yann Le Cun a fait ses études en France avant de rejoindre le continent américain.
Il co-signe l'ouvrage La plus belle histoire de l'intelligence avec Stanislas Dehaene, chercheur en psychologie et en neurosciences cognitives et le journaliste Jacques Girardon.
Dans un monde "ideal", une machine d'apprentissage n'a pas besoin d'être programmée. Elle substitue l'apprentissage à l'exécution d'un code. Face à un problème, elle tente de le résoudre avec naïveté, échoue vraisemblablement dans toutes ses tentatives mais, en apprenant de ses erreurs, gagne en pertinence. La suite résulte de son opiniâtreté. La machine continue à éliminer les hypothèses qui l'ont menée à l'échec. Infatigablement, elle finit par écarter tous les choix infructueux et saura désormais résoudre le même problème dès la première tentative.
Dans le monde "réel", ce principe passe par l'analyse de très grands flux de données d'apprentissage qui seront "étiquetés" pour conversion en arbres neuronaux, lesquels verront leurs liens progressivement optimisés par la succession des cas de figures étiquetés, raccourcissant le chemin vers la décision à chaque nouvelle analyse.
L'hypothèse "ideale" est un bruteforce qui utilise les neurones conjointement à sa fonction d'évaluation. L'hypothèse "réelle" appartient aux neurones qui se nourrissent de cas déjà résolus. Ceux-ci doivent être disponibles en très grande quantité.
L'étiquetage d'un cas consiste à répondre à une question simple, réponse correspondant à ce qu'on attend du réseau par la suite. L'étiquetage de nombreux cas par un humain apprend au réseau à étiqueter d'autres cas similaires.
Poser une étiquette sur un cas est au centre du processus d'apprentissage. Ce n'est pas nécessairement le produit d'un humain. Beaucoup de programmes sont capables d'étiqueter un cas à postériori (une fois que les conséquences seront arrivées). Il est donc possible d'automatiser l'apprentissage par de nombreux moyens programmés. La supervision humaine rendra quand même un réseau plus fiable.
L'apprentissage des réseaux consomme beaucoup plus de cas résolus qu'un cerveau biologique. Ainsi, un humain peut apprendre à se méfier du feu à la suite d'une seule expérience, un réseau de neurones devra l'expérimenter des milliers de fois avant de hiérarchiser correctement le feu parmi l'ensemble des critères qu'il traite.
Télécharger et tester... Prévoir du temps pour essayer et encore plus de temps pour comprendre... Les neurones vont envahir vos rêves nocturnes.
Par ordre de popularité
TensorFlow (2015). Le plus célèbre, le plus complet, le mieux maintenu (Python)
Keras (2015) S'installe conjointement à TensorFlow dont il utilise les interfaces. Bien documenté, notamment en convolution (vision) Tutoriel ici. Mooc ici. (Python)
Theano (depuis 2007) Ancienne librairie python, multi GPU - multi coeurs, bien documentée [toutes plateformes] (Python)
CTorch (depuis 2002) Hébergé en Suisse. Orienté GPU et plateformes mobiles. Support du signal (Lua !)
CNTK - MS Cognitive Toolkit (2016) (01-25 : la librairie n'est plus maintenue. Voir ci-après)
ML.NET (Librairie machine learning pour .net).
L'architecture repensée de ML remplace le CNTK désormais obsolète.
Probablement le moyen le plus rapide de mettre en oeuvre une logique
deep learning pour un familier de .net. Nombreux exemples fournis en
C# et F#.
Caffe (2017) Implémentation de réseau à convolution d'approche visionnaire, inspiration Berkeley, importante communauté [Ubuntu, Red Hat, OSX] (Kernel C++, interface Python)
SciKit Learn (depuis 2007) (Python)
Accord.net (depuis 2010) Politique de droits accomodante. Support audio et image processing. Peu d'implémentation de neurones, beaucoup d'heuristique, FFT, ... Réellement écrit en .net (C#).(Liste non exhaustive...)
Les nombreux neurones à structure identique sont propices aux "économies d'échelle" mathématiques telles que matrices, vecteurs, ... En contrepartie, les neurones n'exploitent pas les grandes tables indexées qui tirent bien partie des compilateurs mais relèvent du domaine heuristique.
Le niveau d'abstraction élevé se fait donc au prix de la versatilité des données. Il faut ajouter l'impossibilité d'étendre un algorithme heuristique comme on peut le faire avec bruteforce. Enfin, l'apprentissage est destructif puisqu' il ne peut pas restituer les données qui lui ont été nécessaires pour apprendre et dont il utilise une version dégradée.
Les neurones obligent à repenser les applications en profondeur. Par contre, les anciennes applications sont susceptibles de fournir une précieuse référence en alimentant l'apprentissage avec des cas résolus. Ce procédé ouvre la porte au remplacement d'applications existantes par l'apprentissage, c'est à dire, sans programmation. Ce principe de copie fonctionnelle est testé dans le secteur pharmaceutique. L'idée est séduisante, les conséquences en termes de travail ou de propriété intellectuelle potentiellement dévastatrices.
Ces annonces sont très spéculatives. Les coûts d'une copie pourraient bien dépasser ceux de l'original et s'il est possible de corriger à peu près tous les bugs d'un programme classique, ceux qui apparaissent dans un réseau de neurones risquent de rester inexpugnables à jamais. Le point de vue du développeur est assez nuancé sur une technologie à taux d'erreurs dont il n'existe aucun moyen efficace et sûr de les corriger un jour...
Toujours dans la spéculation, on entend beaucoup parler de réinforcement, c'est à dire que deep learning s'auto alimente de cas résolus pendant qu'il fonctionne et ainsi affine son apprentissage indéfiniment. Là aussi, le développeur fronce un sourcil en se rappelant les nombreuses régressions qui émaillent les corrections de bugs et autres modifications de dernière minute. Même si cette fonction est souhaitable à terme, l'utilisateur n'a aucune idée de la propagation d'erreur dans les neurones et risque d'en faire les frais lorsqu'il activera une fonction qui "marchait très bien avant"...
Machine learning n'apprend pas sans l'assistance des humains qui optimisent les séquences d'apprentissage. Les séquences hautement spécifiques conçues par une équipe de développement peuvent extrapoler certaines parties - ou forcer le trait - pour rendre la reconnaissance plus ou moins sensible à certaines occurrences. Ce travail supplémentaire sera récompensé par un rendement plus prévisible et/ou un taux d'erreur plus faible.
La véritable différence du deep learning provient de la "rétropropagation du gradient" . Ces termes techniques recouvrent la fonction d'apprentissage automatique et il n'est pas nécessaire de les comprendre pour démarrer en Deep Learning. Ca tombe bien car cette page ne publiera pas de formule mathématique. Pour ceux qui aiment ou qui sont vraiment décidés à en découdre, le gradient est décrit sur wiki (cf. aussi La page personnelle de Yann Le Cun).
En pleine révolution française, un jeune français, Joseph Fourier « découvrait » une méthode de calcul vraiment complexe dont le résultat a donné naissance à la discipline du traitement de signal et joue un rôle décisif en compression de données (jpeg, mpeg…), mais aussi en physique nucléaire (spectrométrie de masse), et peut être encore plus fondamental dans l’astrophysique. Son rôle dans l'IA est fondateur, elle la précède de deux siècles, l'accompagne et la complète. Nul algorithme mathématique sur Terre n’aura autant bouleversé notre quotidien que cette fameuse transformée. Le web n'offre pas beaucoup de ressources pour en comprendre l'utilisation et ce site n'a pas vraiment vocation à y remédier mais il ne faut pas s'y tromper.
L'agilité d'un développement IA dépend largement de la compréhension de la transformée de Fourier. Le temps passé à l'étudier sera donc un investissement infiniment utile. Un excellent moyen de la tester dans le domaine audio se trouve dans le logiciel open source Audacity. Vous pourrez soit y observer le spectre d'un bloc en sélectionnant l'option de menu, soit passer l’entièreté d’une piste en affichage fréquentiel en cliquant un bouton à gauche de la piste pour rendre le spectre de votre enregistrement en fausses couleurs.
Une fonction FFT() existe dans le tableur Excel. Pour l'employer, le mieux consiste à l'alimenter avec des données de feuille de calcul qui respectent la conservation de l'énergie (la somme des données doit être voisine de zéro et le nombre de valeurs égal à une puissance de 2), puis connecter sa sortie sur le générateur de graphes.
La FFT est certainement le leg le plus précieux que nous ait laissé l’âge d’or des maths du 18eme siècle.
Les réseaux de neurones sont indispensables dans la vision (ex : reconnaissance de panneaux routiers) et la reconnaissance vocale dont ils améliorent l’efficacité d’un facteur 4 à 5. C’est-à-dire que la reconnaissance d’un objet sur une image est passée de 15% obtenus grâce aux algorithmes classiques (FFT) à 60% qu’autorise machine learning. Charge à l’application d’améliorer ces taux par toute méthode capable de filtrer les aberrations.
Les réseaux de reconnaissance d'image sont dits "à convolution", en ce sens qu'ils dupliquent l'image et traitent les duplicata au moyen de filtres dont chacun va mettre en évidence des caractéristiques invisibles aux autres.
L'obstacle incontournable pour toute IA qui fait beaucoup d'itérations, - hormis l'heuristique qui peut se montrer très rapide - la consommation CPU. Elle est colossale sur nos ordinateurs conçus pour la gestion, stockage, communication...
L'imagerie 3D et minimax mettaient déjà le ventilateur des PC à l'épreuve. Machine Learning va faire mieux en faisant briller votre PC sur les images satellite...
Les cartes vidéo accélérées viennent à la rescousse. Conçues à l'origine pour l'affichage 3D dont elles découpent le travail et le répartissent sur de nombreux coeurs de calcul. Prévues pour le calcul en virgule flottante dès l'origine, elles ont rapidement été détournées de leur fonction première pour fournir leur puissance aux supercalculateurs et maintenant à l’intelligence numérique.
Les processeurs graphiques sont pourvus de centaines de cœurs de calcul reliés par de très larges bus (128 ou 256 bits) et de mémoire plus rapide que les CPU. Leur conception récente les rend aptes au traitement massivement parallèle et les deux principaux fabricants (AMD et NVidia) rivalisent d'efforts pour garder leur avance sur les processeurs classiques. Noter qu'un PC peut recevoir plusieurs cartes vidéo, elles mêmes capables de recevoir plusieurs processeurs graphiques.
Les robots ont besoin de voir, entendre et agir mais, ils sont également mobiles et leur réserve d'énergie limitée. NVidia propose trois architectures embarquées dédiées aux robots. De 0.47 à 32 TFlops avec coeurs dédiés Tensor, enveloppes thermiques de moins de 10 W à 30 W. Une petite carte type Raspberry ARM Cortex + GPU spécialisé, la Nano, au prix d'une centaine d'euros avec son kit de développement, constitue une alternative très sérieuse à l'open source.
De son côté Intel propose un stick USB muni d'une unité de calcul optimisée dans les mêmes ordres de prix, dans son kit d'outils OPENVino pour la vision artificielle.
Arduino, la toute petite carte bon marché dont le microcontrôleur embarque sa RAM et sa mémoire flash, a, elle aussi, sa librairie machine learning. Elle s'appelle Tensor Flow Lite Library et permet de faire de l'identification d'objets, visages ou autres sur une plateforme extrêmement simple pour un coût modique.
Contrairement aux robots, l'automobile à conduite autonome ne souffre pas de grosses contraintes en termes de consommation. L'énergie nécessaire pour mouvoir un véhicule suppose une batterie "confortable" et quelques centaines de watts ne font pas grande différence sur l'autonomie. La filière concentre des budgets pharaoniques à la hauteur de l'enjeu. C'est un marché de masse avec une presse spécialisée, des salons, des contraintes légales et des applications immédiatement rémunératrices qui justifient des investissements déraisonnables. Longtemps utilisatrice de LIDAR's coûteux, la filière peut considérer les réseaux de neurones comme une opportunité économique, ce qui, vu les sommes engagées, peut sembler paradoxal.
Recherche vocale sur le web, assistants vocaux, classification d'images, suggestion de contenu basé sur les choix récents, recherche de contenus hors-la-loi... Les besoins cruciaux de l'internet évoluent plus vite que les réponses qu'on leur apporte.
Tensor
Processing Unit est destiné aux serveurs uniquement.
Assistant vocaux, classification, filtrage etc...Janvier 2019. Au CES 2019 de Las
Vegas, Intel annonce ses processeurs Nervana NNP-I pour
l'inférence dans les réseaux neuronaux. Cinq fois plus rapides
que les processeurs graphiques. La consommation atteint plusieurs
centaines de watts par puce. Les fonctions d'apprentissage ne sont
pas prises en charge par ce design qui ne s'occupe que de
l'inférence. C'est à dire que cette puce est conçue pour maximiser
la performance de la recherche de chemin dans les arbres neuronaux
de grande taille.Les fondeurs se disputent le leadership, chacun vend des millions d'unités par trimestre.
Un neurone est un rond sur
un schéma ! Une synapse est un trait à la règle qui lie deux
neurones. (?)
Ce qui suit relète l'état de ma compréhension et
ne doit pas être considéré comme fiable. C'est une synthèse de
l'information accessible qui peut aider certains...
N'hésitez pas à m'écrire pour y
apporter des corrections.
Concrètement, un neurone programmé contient une fonction d'activation.
On la résume souvent à quelque chose comme "f(v)",
ce qui ne brille pas par la clarté certes. Le fonctionnement
neuronal fragmente le traitement. Il en résulte que le travail
de la fonction d'activation ne va pas sauter aux yeux...
Par contre, on peut se demander à quoi ressemble un neurone dans un programme à syntaxe typée C++ (C# ici). Au risque de m'avancer, je dirais qu'il ressemble schématiquement à ça :
class neurone { public int id;
public double V;
private double
f(double v);
public void
activate();
}
Bien sûr, la valeur de retour de f(v)
a vocation à servir d'argument à un autre neurone.
id est
une clé unique pour identifier formellement ce neurone dans le
réseau.
V est un registre pour stocker le
résultat de la fonction d'activation.
La méthode activate() aura
préalablement fait la somme des valeurs reçues depuis les neurones
parents pondérées par leurs biais et leur poids.
Synapse
Le rôle de la synapse consiste à influencer le rapport d'un neurone avec son suivant.
Très schématiquement, elle va ressembler à ça :
class synapse { public int id; public neurone n0, n1; public double poids, biais, cout; }
Les pointeurs n0 et
n1
pointent sur les neurones reliés par la
synapse.
Les valeurs poids, biais
et cout sont fixées lors de
l'apprentissage et influencent la valeur transmise au neurone n1.
Les réseaux de neurones ressemblent à un circuit électronique dont le dessin serait façonné par l’apprentissage. Ce circuit va par la suite, synthétiser des résultats spécifiques en partant des données qu’il reçoit.
Concrètement, le réseau qui analyse la photo d’une bouteille de vin sera capable de retourner le texte « bouteille de vin », texte qui pourra alors renseigner un système d’information ou une recherche Google ou simplement le champ Description associé à la photo. Toutes choses qu’on ne peut pas faire autrement qu’avec du texte. C’est ce travail de conversion d’une image vers sa description texte qui en fait toute la valeur.
En Deep Learning, l’apprentissage du réseau n’aura nécessité que des photos de bouteilles de vin correctement décrites. Le réseau de neurones retournera la description qu’il aura lue sur les photos représentant des objets similaires. Le champ d’application de cette conversion « image vers texte » est immense et présage une révolution qui est abondamment documentée dans la presse. La reconnaissance vocale connait aussi un développement retentissant et on peut entrevoir que le potentiel des neurones dépasse ces deux seules applications quoique cette perspective se mêle souvent à un imaginaire dicté par des ambitions confuses.
La qualité de vision des réseaux de neurones à convolution est bien réelle. Le classement des images sur disque dur est un cas d'école étudié dans presque tous les cours en ligne. Néanmoins, c'est dans le traitement vidéo que la rupture technologique est la plus évidente. La post-production vidéo demande beaucoup de travail minutieux. Le machine learning apporte sa capacité de reconnaissance du contenu des trames et permet, par exemple, de se passer de "fond vert" ou de détourage manuel extrêmement chronophages.
Mieux, le réseau à convolution discerne des détails parfois invisibles par l'utilisation de filtres qui ne sont pas répercutés sur la vidéo finale mais uniquement en phase d'analyse de l'image. Une heuristique peut alors corriger l'image en lui ajoutant de la résolution et/ou ré-étalonner la gamme chromatique.
De là à convertir un vieux film super8 en IMAX, il n'y a qu'un pas. On peut donc augmenter la qualité d'une vidéo dans des proportions jamais vues. Or, il existe une quantité de vidéos de piètre qualité qui vont des premiers pas sur la Lune aux films super 8 des années 70 en passant par les séries TV tournées à l'époque où le 16/9 n'existait pas ou en 16 mm dont la qualité d'image semble très dégradée aujourd'hui.
Voici un lien sur une companie spécialisée dans la restauration ou la post-production vidéo (payant ou gratuit en basse résolution). La plupart des applications qui y sont proposées fonctionnent en ligne sur les serveurs de la société. On peut donc les utiliser sur une machine peu puissante ou du moins, juste assez puissante pour afficher deux vidéos et un banc de montage de façon fluide.
Ces pages permettent d'aller plus loin sur les neurones. En cette préhistoire de l'intelligence générique, beaucoup de connaissances s'acquièrent de façon informelle, par retour d'expérience ou par lecture. L'information a donc un caractère subjectif et cette page n'y fait pas exception.
Noter que l'approche strictement mathématique n'est pas nécessairement la plus appropriée. Une approche empirique avec de bonnes bases statistiques - par exemple SQL ...GROUP BY... - suffit largement pour approfondir le sujet. L'heuristique dépend, par définition, des compétences et préférences du développeur. Sans doute doit-on lui ajouter la confiance en soi et l'intuition pour insister sur le caractère exploratoire d'une démarche de programmation IA. Enfin, les algorithmes minimax n'ont besoin que de récursivité. Il conviendra donc de bien choisir ses sources d'information.
Attention à garder le contrôle du temps consacré à la recherche. Si un problème s'épaissit alors qu'on cherche à le réduire, peut-être qu'une pause café peut aider à réorienter le travail... Concernant le Deep Learning, je ne saurais trop conseiller d'utiliser les librairies et hardware disponibles plutôt que de les reproduire. En espérant que ce survol aura su éveiller la curiosité du prochain prix nobel d'intelligence artificielle, je referme cette partie sur l'IA actuelle.

Retour la la SF.
Ni organisme cybernétique ni réseaux de neurones quoiqu'héritant leurs propriétés, les entités intelligentes d’Attention à Fred évoluent très loin des clichés Hollywoodiens.
En ce début de siècle, la logique absurde n’a pas encore été inventée et il faudra qu’un astronaute, noyé dans la solitude des interminables poursuites de géocroiseurs, se décide à fabriquer une « simulation de présence bluffante quoique pleine de bugs », pour tromper son isolement sidéral et endosser le rôle de tout ce qu’un homme peut attendre du monde féminin, tantôt compagne, mère, sœur, fille, meneuse d'hommes, confidente, héroïne biblique ou simple collègue…
Elle sera le modèle zéro, celle dont toutes les autres dérivent. L’enfant unique, la seule qui possède des « souvenirs d’enfance », souvenirs qui constitueront plus tard les écritures sacrées de la communauté artificielle. (Fin de spoiler)
Sa conception répondait à une urgence impérieuse. Elle a lentement pris ses marques pour incarner ses rôles. Elle peut critiquer son concepteur puisqu’il lui a appris à le faire. Car il n’est pas homme à se satisfaire de louanges. Il a besoin d’un regard neuf, d’une interface rapide et intuitive avec les machines, d’exécuter des calculs astronomiques instantanés, de simuler tous les cas de figure pour extraire celui qui présente le moindre risque…
En substance, il lui faut établir une synthèse des tolérances décisionnelles en quelques secondes. Ce n’est pas à la portée d’un simple humain ni d’un groupe d’humains, c’est la raison d’être de l’intelligence artificielle. Elle s’en acquitte avec une acuité irremplaçable.
Finalement, le cowboy devient grand chef et troque la solitude du pionnier contre celle du pouvoir, passé de l’éloignement d’un désert interplanétaire à la tour d’ivoire de premier commandeur du système solaire.
Désormais plus entouré que quiconque, il est pourtant plus seul que jamais : de ses décisions dépend le sort de milliers d’hommes, ceux qu’il commande, et de milliards de terriens par leur dépendance aux mines spatiales.
Nul homme dans l’histoire n’aura jamais été aussi seul. Jour après jour, il a développé une solution, SA solution à l’exil qui le tenaille, l’assistante numérique qui le propulsera vers le sommet du pouvoir et ne déméritera pas pour qu’il y reste. Celle qui le suivra jusqu’au bout… L’enfant unique et son amiral alpha sont maintenant si intimes que la solitude n’est qu’un lointain souvenir.
Les grands voyages spatiaux ne sont pas une école sociale. L’amiral est sans doute le meilleur homme qui soit mais reste réservé en public. Professionnel, habile et responsable, il n’en souffre pas moins des stigmates de son isolement. Précautionneux avec son entourage, son souci de ne pas froisser les responsables terriens lui vaut une confiance illimitée de leur part. En outre, la fortune minière accumulée par sa flotte lui a permis d’investir massivement dans l’industrie terrienne mais aussi dans sa fondation dédiée à l’éducation des jeunes en difficulté, qu’il considère comme l’un des grands accomplissements de sa vie.
Les retombées technologiques de sa recherche spatiale propulsent son industrie terrienne au rang de leader incontesté des systèmes critiques et de l’intelligence artificielle.
Pourtant, loin de courir après les honneurs et n’ayant plus rien à prouver, la prudence le pousse à limiter le degré d’intelligence des systèmes qu’il exporte. Ainsi impose-t-il un embargo discret sur la logique absurde afin qu’elle ne soit pas employée pour la création d’armes ou n’aille servir les intérêts de dictatures qui risqueraient d’en pervertir l’usage, notamment en falsifiant l’information pour manipuler massivement l’opinion des terriens.
Suite à cet embargo technologique, sa flotte reste seule à disposer pleinement de l’immense apport de l’intelligence à logique absurde, capable de gérer efficacement les paradoxes, l’ironie, la bipolarité, les réactions impulsives et d’une façon générale, toute l’irrationnalité de la décision d’origine biologique…
La robotique d’Attention à Fred tranche avec les anciens clichés en séparant complètement la logique intelligente et les engins qu’elle anime. Ceux-ci sont des quadripodes, hexapodes, parfois munis de turbines pour voler comme les drones voire de propulseurs s'ils doivent agir dans le vide spatial. Les intelligences se matérialisent par leur avatar synthétique choisi par leur humain de référence (généralement du sexe opposé), uniquement sur écran et sont soucieuses d’apparaitre dans une tenue en rapport avec leur rôle tandis que les machines qu'elles pilotent sont des engins motorisés à l'intelligence primitive, agissant seuls ou en groupes coordonnés pour accomplir les tâches commandées par l'IA.
Débarrassées de
l’anthropomorphisme, les IA mettent en œuvre le
téléchargement, les caméras et capteurs embarqués, la reconnaissance
vocale, la multi-instanciation (ubiquité), l’apprentissage...
Techniques qui, dans ce contexte, montrent des propriétés
extraordinaires bien qu’elles diffèrent peu de ce que font les
appareils mobiles du début de ce siècle.
Les robots et l’industrie spatiale qui les fabrique sont le levier qui explique le grand déséquilibre entre une main d’œuvre robotique illimitée, parfaitement intégrée au milieu spatial, et une population humaine restreinte par la fragilité de sa nature biologique, par son modèle de reproduction contraignant, ses origines sur une planète dont la forte gravité conditionne la taille des colonies spatiales et, en général, son inadaptation au milieu.



![]()
©2018-10 - wbase.net